ELMo-Embeddings from Language Model
by indexxlim
ELMo(Embeddings from Language Model)
이번 포스트는 2018년 상반기에 나왔던 ELMo에 대해 리뷰를 하고자 합니다. ELMo는 세서미 스트리트(Sesame Street)라는 어린이용 인형극 애니메이션에서 나온 이름으로 Embeddings from Language Model의 약자입니다. 직역하면 언어모델부터 임베딩으로, 결국 언어모델을 사전 훈련(Pre-trained)했다는 이야기겠죠?
여기서 사전훈련 모델에 대해 잠깐 이야기하자면, 단순히 정확도만으로 생각한다면 Bert를 사용해야 된다고 생각 할 수 있습니다.
하지만 Bert는 큰 결점이 있습니다. 기본 모델의 Layer의 갯수가 12, 히든 레이어의 차원수가 768로 너무 크기 때문에 반드시 고사양 환경이 필수적이라는 것입니다.
Bert Base와 GPT-2 Base 모델들의 파라미터 갯수는 대략 110milion이고 ELMo의 Small모델은 13milion, Medium모델은 28milion으로 많은 차이가 나기 때문에 비교적 장점이 될 수 있습니다. ALBert와 Bert-small은?
그래서 사용자의 관점에서 CBOW, Skip-Gram 같은 모델부터 ELMo, GPT-2, 그리고 Bert 까지 환경을 고려해서 차선택을 골라 합리적인 모델링을 할 수 있습니다.
여기까지 모델링의 관점에서 차선택을 위해서 알고 있어야 한다는 관점이었고,
또한 ALbert와 Bert-small 등의 모델의 결과와 비교하기 전에 ELMo의 이름이 인상적입니다.
원론적으로 ELMo - Embeddings from Laguage Model이라는 개념은 대대수의 모델링과 같은 개념이라고 생각되는데요.
언어모델은 각 단어가 등장할 확률을 할당(assign)한 상태공간(state space)이고, n-gram 이상이 적용 되면 그 상태(state)는 단어 확률 변수의 마르코프 연쇄로 이루어집니다.
그 예로 은닉 마르코프 모형(hidden Markov model, HMM)에서는 은닉 상태(hidden state)와 관찰가능한 결과를 통해 상태확률 혹은 우도(likelihood)를 계산합니다.
여기서 신경망까지 나간다면, SVDL에서는 interpretation of a simple RNN as the maximum likelihood estimate of a state space model that follows deterministic dynamics 라고 합니다.
그래서 신경망과, 언어모델, 그리고 임베딩까지, ELMo의 구성요소를 알아보겠습니다.
1. LM
ELMo는 LM에 기반하여 학습을 진행합니다.
통계학적으로 Language Model(LM)이란 일종의 확률분포(pobability distribution)입니다. 언어모델은 단어가 m개가 주어졌을때 각 단어의 확률 P(w1 … wm)을 가지고 있습니다.
언어모델은 대다수의 자연어의 모델에 사용되는데, 이미지가 어떤 필터(filter)가 포함되어 있는지를 특징으로 학습한다면, 자연어는 각 단어의 확률분포로부터 단어 조합의 확률분포를 학습한다고 의의를 둘 수 있습니다.
n-gram개의 단어로 이루어진 문장의 확률을 계산한다면 마르코프 체인 법칙(Markov chain rule)을 통해 계산 할 수 있습니다.
이 최대 우도 추정(maximum likelihood estimation) 수학적인 도출은 $∏\limits_{i=1}^{n}P(w_i)$
하지만 언어의 확률 분포를 근사모델링할 때는 문제가 있습니다. N-gram으로 이루어진 문장의 확률분포에서 도중에 단어가 없을 경우 확률 계산이 되지 않습니다.
이를 희소문제(sparsity problem)라고 합니다.
이를 해결하기 위해 N-gram models는 스무딩(smoothing)이나 백오프(backoff)등의 다양한 방법을 사용합니다.
이중 backoff는 없는 단어는 제외하고, 각 n-gram에 가중치를 부여하는 등의 방법입니다.
Smoothing는 다음과 같은 Adjusting 절차를 걸칩니다.
MLE unigram probabilities 은 다음과 같을 때, $P(wx) = count(wx) \over N$
$N$은 $∑w count(w)$이고 $V$는 $vocab size$ 라고 했을 때, Add-one smoothing은 다음과 같은 절차를 지납니다.
Smoothed unigram probabilities $P(w_x) = count(w_x) \over (N+V)$
Adjusted counts (unigrams) $c_i^* = (c_i+1) {N \over (N+V)}$
MLE bigram probabilities $P(w_n|w_{n-1}) = {count(w_{n-1}w_n ) \over count(w_{n-1})}$
Laplacian bigram probabilities $P(w_n|w_{n-1}) = {count(w_{n-1}w_n )+1 \over count(w_{n-1})+V}$
Simple linear interpolation $P(w_n|w_{n−2}w_{n−1}) = λ_3P(wn|w_{n−2}w_{n−1}) + λ_2P(w_n|w_{n−1}) + λ_1P(w_n)$
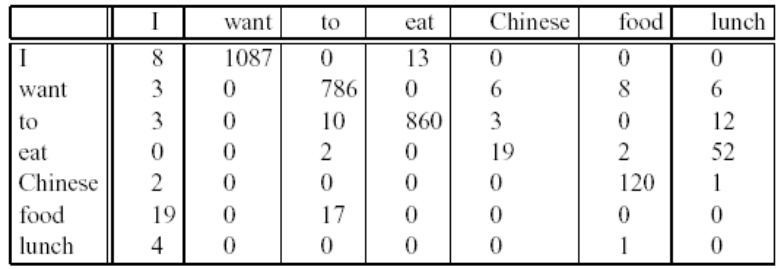
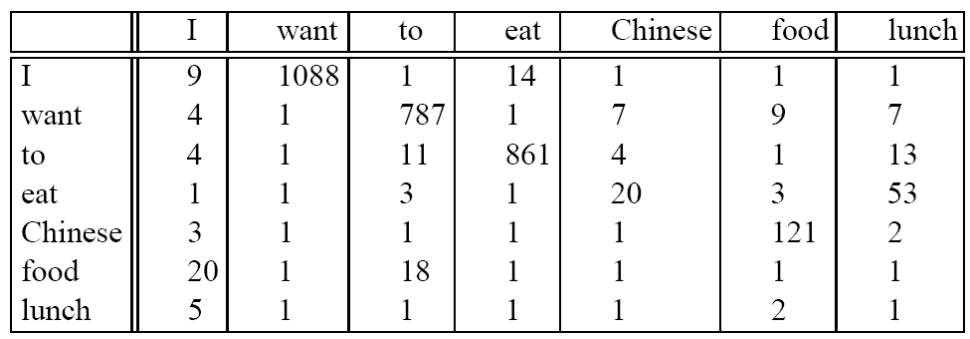
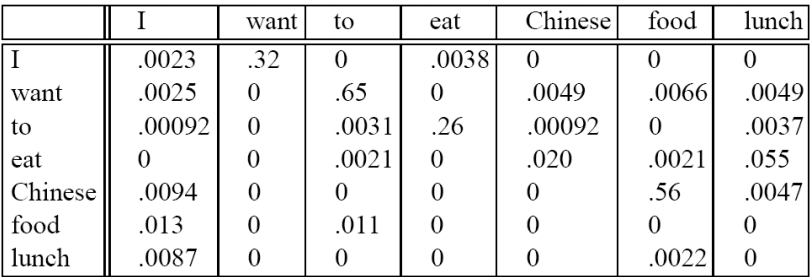
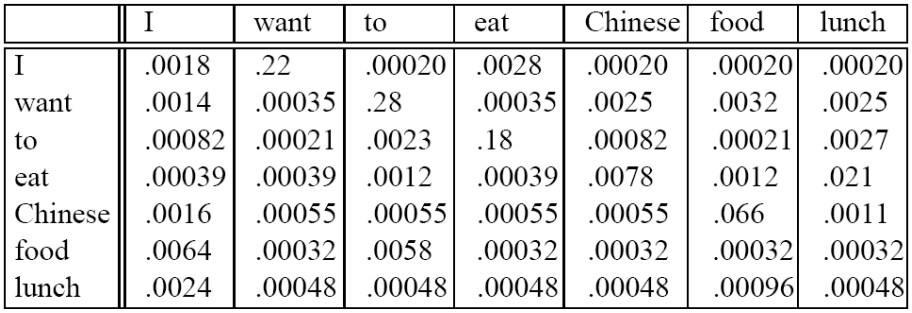
직접적으로 Add-one smoothed bigram probabilites을 살펴보면 다음과 같은 테이블이 나옵니다.
 |
 |
 |
 |
-Newral Network Laguage Model(NNLM, Embedding)
그 이후 통계적 언어 모델은 Newral Network Laguage Model(NNLM)이라는 신경망 언어모델로 발전하였습니다.
이는 단어 간 유사도를 반영한 벡터를 만드는 워드 임베딩(word embedding)으로 다양한 알고리즘으로 발전하였습니다.
워드 임베딩은 Structure Preserving라고 표현 할 수 있는데, 이 임베딩 벡터는 초창기에는 one-hot vector를 변형하면서 생긴 하나의 층(projection layer)입니다.
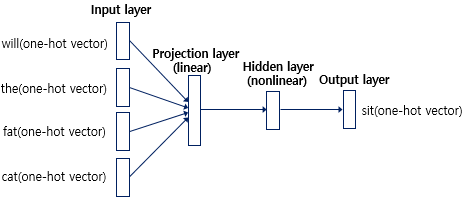
one-hot vector는 너무 넓게 분포가 되어있기 때문에(희소 행렬, sparse matrix), lookup table이라는 단어의 벡터를 합치는 과정과 선형 층(linear layer)를 거쳐, 신경망(nonlinear)과 소프트맥스(softmax)를 통해 단어가 등장할 확률을 학습합니다. 이중 선형 층은 활성화 함수(activation function)을 적용하지 않고 그대로 출력으로 나가는 층을 가르킵니다.(function) Word2Vec 등의 임베딩들은 이렇게 희소 표현을 분산 표현(distributed representation)으로 표현하면서, 중심단어 혹은 주변단어의 등장 확률을 통해 각 단어의 벡터를 학습해 나가게 됩니다. 그 후 임베딩은 동시등장단어를 계산(GloVe)하고, charactor-level로 단어를 쪼개고(FastText), attention을 붙이는 등의 워드 임베딩이 등장하고 있습니다.

이렇게 각 단어가 n-gram 안에 동시등장할 확률을 학습한
-Perplexity
퍼플렉시티(perplexity, PPL)은 언어 모델의 성능을 측정하기 위한 정량 평가(explicit evalutation) 중 하나입니다.
$PPL(w_1, w_2, w_3, … ,w_n) = P(w_1, w_2, w_3, … ,w_n)^{-1\over {n}} = \sqrt[n]{1 \over {P(w_1, w_2, w_3, … ,w_n)}} = = \sqrt[n]{1 \over {∏\limits_{i=1}^{n}P(w_1, w_2, w_3, … ,w_n)}}$
n-gram의 경우에는 체인룰이 적용되어 전체 문장대비 각 단어의 등장 확률을 분모로 가져가고 있습니다.
2. ELMo
먼저 논문의 abstract입니다.
“deep contextualized” 의 새로운 타입을 소개한다.
ELMo는 (1) 단어 사용의 복잡한 특성(Syntatic and Semantic, 구문과 의미론)을 모두 내포하며 (2) 이러한 용도가 언어적 맥락(다의어나 동음이의어)에 따라 어떻게 달라지는지 표현(word representation) 할수 있는 사전학습(pre-training) 모델이다. 단어 벡터는 대형 텍스트 말뭉치를 통해 양방향 언어 모델(biLM)로 내부적으로 학습했다. 이러한 벡터들이 기존 모델들에 쉽게 추가될 수 있고 질문 답변, 문자 첨부, 감정 분석 등 6가지 NLP 문제에서 개선할 수 있었다.
ELMo의 representations은 전체 입력문장을 사용하고, 양방향 LSTM을 통해 유도된 벡터는 대형 말뭉치에 기반한 언어모델을 목표로 학습된다. 구체적으로는 최상위 레이어(top LSTM layer)만 사용하던 기존과 달리 쌓인(stacked) 입력 데이터를 모두 결합해서 사용하기 때문에 성능이 좋다.
저자는 Intrinsic evaluation을 통해서 higher, lower level 특징을 파악할 수 있었는데, Intrinsic evaluation은 만들어진 임베딩 벡터를 평가할 때 Word analogy와 같은 Subtask를 구축하여 임베딩의 품질을 특정 중간 작업에서 평가하는 방식이다. Real task의 정확도를 통해서 임베딩의 품질을 평가하는 것이 아기 때문에 유용성을 판단하기 위해 실제 작업과의 긍정적인 상관관계 분석이 필요하다.
higher-level LSTM : 문맥을 반영한 단어의 의미를 잘 표현함
lower-level LSTM : 단어의 문법적인 측면을 잘 표현함
한줄로 표현하면 문맥에 따라 단어의 의미를 다르게 파악한다는 것입니다. 따라서 동일한 단어가 항상 동일한 벡터로 변환되지 않고 다른 벡터로 변환될 수도 있다고 이야기합니다.
-Bidirectional language models
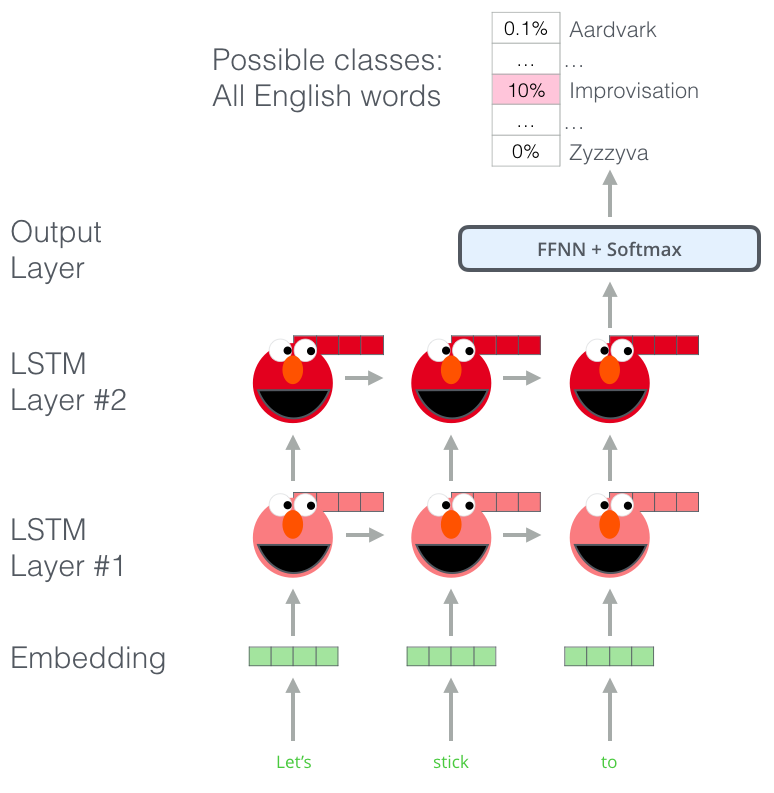
먼저 ELMO의 전체적인 구조는 다음과 같습니다.
들어가기 앞서 표기를 정리하면
| 표기 | 값 |
|---|---|
| $task$ | 하려는 작업 |
| $t$ | token |
| $k$ | time-step |
| $γ^{task}$ | hyper-parameter |
| $s_j^{task}$ | softmax-normalized weight |
| $h_{k,j}^{LM}$ | 모델의 j번째 레이어, k번째 단어에서 나온 hidden state. |
주어진 문장이 N개의 token으로 이루어져 있을때, language model은 에 대해 $t_k$의 확률을 모델링함으로써 문장의 확률을 구합니다.
Bidirectional라는 이름 그대로 forward LSTM 과 backward LSTM 두 가지의 방향으로 구성되어 있습니다.
최근 논문이 나올 당시의 언어 모델들은 Bi-LSTM을 통해 문맥과는 독립적인 token 표현 $x_k^{LM}$을 만들어냅니다.
여기서 두가지 수식의 차이점은 forward는 $(t_1,t_2,…,t_k)$ 즉 k번째 이전까지의 토큰을 사용한다는 것이고, $(t_{k+1},…,t_N)$ backward는 k번째 이후의 토큰을 사용합니다.
그 후에는 LSTM을 통해 L개의 layer를 통과시켜 각 token의 위치 k에서, 각 LSTM layer는 문맥에 의존되는 표현 $h_{k,L}^{LM}$을 생성시킵니다.
LSTM layer의 가장 최상위층 output인 $h^{LM}_k,L$은 softmax layer를 통해 다음 토큰인 forward에서 $t_k+1$ 혹은 backward에서 $t_k-1$ 을 예측하는 데에 사용합니다.
BiLM은 forward LM과 backward LM을 모두 결합한 형태인데, 다음의 식은 정방향 / 역방향의 log likelihood function을 최대화시킵니다
$∑\limits_{k=1}^N(logp(t_k|t_1,…,t_{k−1};θx,θ→LSTM,θs)+logp(t_k|t_{k+1},…,t_N;θx,θ←LSTM,θs))$
token 표현 $θ_x$와 $softmax\ layer\ θ_s$의 파라미터를 묶었으며, 각 방향의 LSTM의 파라미터들은 분리시킨 채로 유지하였습니다.
저자의 이전 연구들과 다른 점은 파라미터들을 완전히 독립적으로 사용하기보다는 forward와 backward계산에 일정 weight를 공유하도록 했습니다.
-ELMo
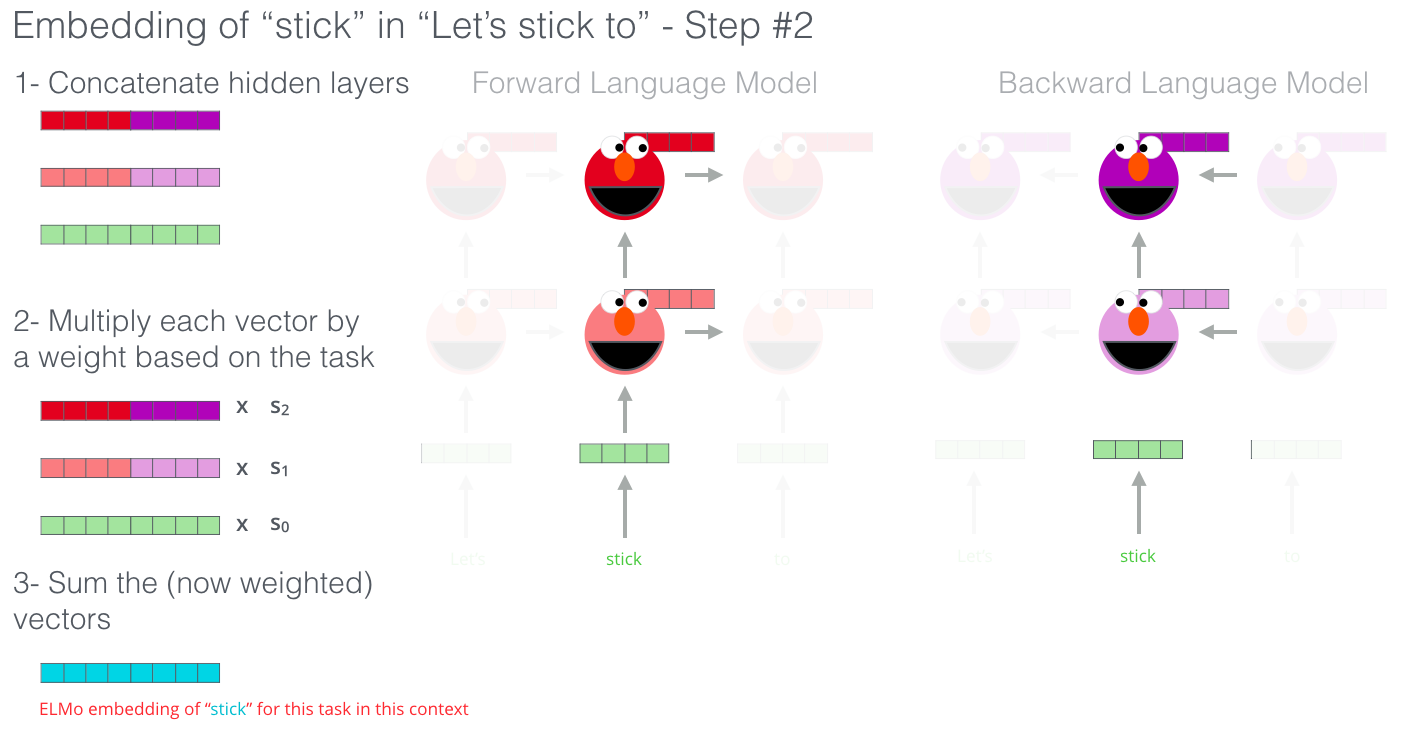
ELMo는 biLM에서 등장하는 중간 매체 layer의 표현들을 특별하게 합친 것을 의미하는데, 각 토큰 $t_k$에 대하여, L개의 layer인 BiLM은 2L+1개의 표현을 계산합니다.
이 때, $h_{k,0}^{LM}$은 token layer를 뜻하고, $h_{k,j}^{LM}=[h_{k,j}^{→LM};h_{k,j}^{←LM}]$ 는 biLSTM layer를 의미합니다. 그래서 모든 layer에 존재하는 representation을 R로 single vector로 혼합하는 과정을 거칩니다:
예시로, 가장 간단한 ELMo 버전은 가장 높은 layer를 취하는 방법이 있습니다 : $E(R_k)=h_{k,L}^{LM}$. 이 ELMo는 task에 맞게 또 변형될 수 있습니다.
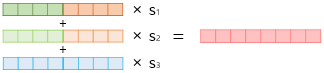
$s^{task}$는 softmax-normalized weight를 의미하고 $γ^{task}$는 regularization으로 task model을 전체 ELMo vector의 크기를 조절하는 역할을 맡습니다.
3. 사용
ELMo의 사용은 논문에 따르면 입력으로 CNN으로 1차적으로 학습되어진 값을 사용했다고 합니다. 128개의 필터로 학습되어진 16차원의 임베딩을 사용해서 돌렸습니다. 그리하여 학습이 다 되었을때 Word2Vec이나 GloVe와 같이 입력이 되기도 합니다.
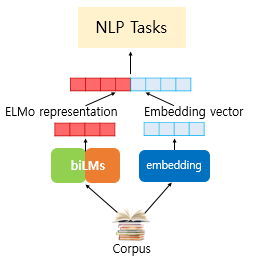
즉 Elmo의 context vector와 코퍼스의 의미를 모두 포함한 vector와 병행되어 사용되는것으로 보입니다.
import tensorflow_hub as hub
elmo = hub.Module("https://tfhub.dev/google/elmo/1", trainable=True)
감사합니다!!
Reference
•N-gram models •Statistical Parametric Speech Synthesis •Intrinsic evaluation •SVDL •wikidocs •function •The Illustrated BERT, ELMo, and co.
Subscribe via RSS