Summarization based on word importance
by indexxlim
Improving the Estimation of Word Importance for News Multi-Document Summarization 논문을 참고하여 특징에 기반한 요약기를 실험해보려고 합니다.
지난 포스트에서 추출요약의 몇가지 방법에 대해 간단히 소개를 했습니다.
이번 포스트는 추출요약에 사용할 특징들과 그 특징이 얼마나 유효성을 가지고 있는지에 대한 판단, 그리고 이 특징들에 대한 결과를 비교해보겠습니다.
먼저 추출요약에 사용할 특징들입니다.
Word Importance
문장의 중요성을 판단하기 위해서 사용하는 가중치 중에 하나로 단어에 대한 특징을 뽑습니다.
논문에는 frequency feature, word type, KL-Divergence, NYT-weight, Unigram, Context feature, 그리고 MPQA and LIWC dictionary 등을 사용해서 문장의 중요도를 판답합니다.
이 특징들을 선형회귀를 이용해서 뽑은 p-value로 검증하여 각 특징에 대한 가설이 얼마나 근거있는지 판별해보도록 하겠습니다.
이 특징들 중에서 몇몇은 유료로 판매되고 있는 사전이기때문에 현재 쉽게 사용 할수 있는 특징들을 이용해서 단어의 가중치를 추정해보겠습니다.
각 현재 실험해볼 특징으로써는
1. LLR chi-square static value (and MRW scores)
2. KL(P,Q)
2. earliest first location
3. latest last location
4. average location
5. average first location
6. appears in the first sentence
7. the number of times it appears in a first sentece
7. POS of word
8. NER of word
Propability and Frequency
위에서 나열한 특징들은 기본적으로 확률과 빈도에 기반한 특징들입니다.
단순한 단어의 확률 분포를 통해 요약한 알고리즘인 SumBasic의 절차는 다음과 같다고 작성되어 있습니다.
Step 1 Compute the probability distribution over the words wi appearing in the input, p(wi) for every i; p(wi) = n N , where n is the number of times the word appeared in the input, and N is the total number of content word tokens in the input.
Step 2 For each sentence Sj in the input, assign a weight equal to the average probability of the words in the sentence, i.e.
weight(Sj) = P wi∈Sj p(wi) {wiㅣwi ∈ Sj}ㅣ
Step 3 Pick the best scoring sentence that contains the highest probability word.
Step 4 For each word wi in the sentence chosen at step 3, update their probability
pnew(wi) = pold(wi) · pold(wi)
Step 5 If the desired summary length has not been reached, go back to Step 2.
기본적으로 greedily 탐색 하지만 이 요약 방법은 Harry Poter Summary에서 보면 적절한 요약 문장을 선별하지 못하는 것으로 보입니다. 그래서 이런 확률에 추가적인 알고리즘을 더하여 특징을 변경 시켜보겠습니다.
LLR chi-square static value (and MRW scores)
LLR 을 계산하기 위해서는 기본적으로 텍스트에서 확률을 계산하기 위한 이항 분포(Binomial distribution)를 가정합니다.
그래서 원본 데이터와 요약데이터를 나눠 표본으로 만들고, 이 표본에서 최대 우도 측정을 사용해서 P를 계산합니다.
1. p = (count-of-w-in-original + count-of-w-in-abstract) / (original-size + abstract-size) = (c1 + c2) / (N1 + N2)
2. p1 = c1 / N1
3. p2 = c2 / N2
L(c1)과 L(c2)는 원본과 요약데이터에서 단어가 발생할 확률인데 이항 확률 공식 Binomial Probability Formula을 이용합니다
이 때 smoothing 기법을 이용하여 계산합니다.
KL-divergence Feature
KL은 확률분포 P와 Q사이의 차이를 계산합니다.
P는 joint probability(log-likelihood)로, Σpi = 1.0이고 Q는 (y1 : q1, …., P는 (x1 : p1, x2 : p2, …, xn : pn) 일 때, Σqj = 1.0 인 yn : qn).
이제 P와 Q가 동일한 결과 xi에 대해 정의되었다고 가정합니다
이렇게 요약문과 원본 데이터의 joint probability로 각 단어의 분포를 계산합니다.
KL (P, Q) = Σ i = 1..n [p i * log (p i / q i )]
Word Location, Word Type
단어의 위치정보를 계산하여 특징으로 사용합니다. 전체 문장중에 등장하는 위치와, 첫번째로 나타나거나 첫문장에 나타나는 등의 위치 정보를 특징으로 합니다.
또한 이 단어가 NLP의 주요 프로세스라고 할수 있는 Named Entity Recognition(NER), Part of Speech(POS) 정보로 바꿧을때 얼마나 나타내는지를 계산합니다.
Regression-Based Keyword Extraction
회귀분석을 통해 각각의 특징이 얼마나 좋은 특징인지 판별해 보겠습니다. 회귀분석에 필요한 데이터셋은 CNN데이터를 이용하여 어떤 단어가 요약문장에 들어가있는지를 1,0로 라벨링해서 회귀를 실험해봤습니다.
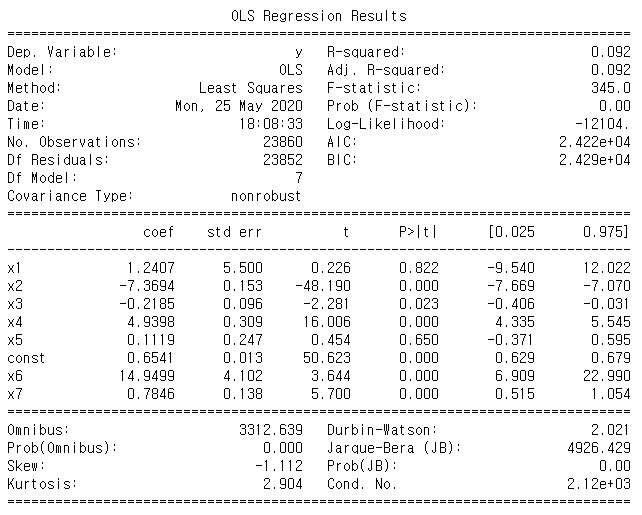 8개의 특징을 가지고 regression 돌린 결과입니다.
8개의 특징을 가지고 regression 돌린 결과입니다.
사진의 결과를 통해 1,3,5번째의 특징에서 p-value > 0.005 이므로 이 특징을 빼고 돌려보면
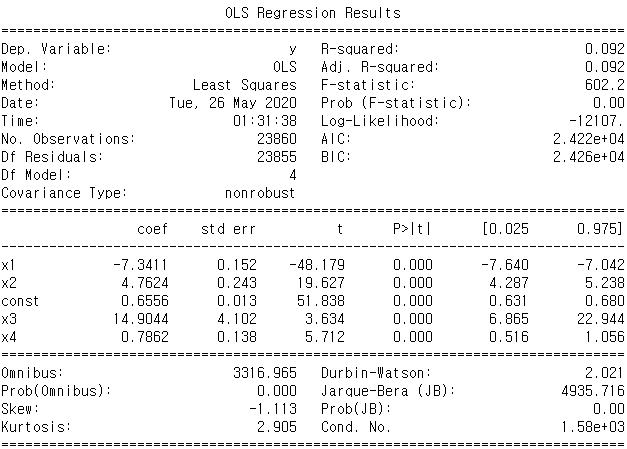 비교적 p_value가 깨끗하게 나옵니다.
비교적 p_value가 깨끗하게 나옵니다.
물론 p-value가 낮다고 해서 실질적 또는 임상적 중요성을 의미하는 것은 아니지만 상관계수를 통한 비교를 통해 통계적인 의미를 찾을 수 있습니다. 이를 통해 rouge점수로 비교해보겠습니다.
Result
Rouge-N 은 문서 요약 분야에서 자주 이용되는 성능 평가 척도입니다.
이 특징에 기반하여 뽑은 문장과 DailyMail Dataset의 요약문을 사용했습니다. 여기서 Rouge-1, Rouge-2, Rouge-L로 평가했고, 그 중 recall 점수로 원본 요약문장 대비 가중치를 이용해 뽑은 문장과 얼마나 겹치는지를 보여줍니다.
8개의 특징을 사용했을때보다
sumr_1 : 0.45541628200940715
sumr_2 : 0.13593530958811012
sumr_l : 0.3443128264616987
p_value가 0.005보다 큰 3개의 특징을 제외했을 때, 아주 미세하게 더 좋은 결과를 보여줌으로써 이 특징이 결과에 필요하지 않다는 것을 증명합니다.
sumr_1 : 0.4558262102595408
sumr_2 : 0.13621171053854797
sumr_l : 0.3446573043118606
Lexrank Rouge점수와 비교해보면
sumr_1 : 0.43921486912181934
sumr_2 : 0.14790742692883918
sumr_l : 0.3266996620839612
Rouge 1-gram일 때와 전체문장으로 비교했을 때 비교적 높은 점수를 얻은 것으로 확인하였습니다.
——————————————————————————-
추후 특징을 추가해서 실험 예정(pretraining Embedding)
Subscribe via RSS