Summarization
by indexxlim
요약에 대한 방법들은 다양하게 발전되어 왔습니다. 먼저 몇몇 구분방법에 대하여 나열하자면 다음과 같습니다.
-
단일문서과 다중문서
summary = summarize(document) 과 summary = summarize(document_1, document_2, …) -
일반(generic) 요약과 질의집중(query-focused) 요약
summary = summarize(document, query)이 때 차별성에 중점을 둔다면 업데이트 요약이 됩니다 -
지시적(indicative) 요약과 정보적(informative) 요약
특정 종류의 메타데이터를 바탕으로 한 요약, 문서의 전체정보를 통한 요약
그 외에 업데이트요약, 키워드요약, 헤드라인요약, 감성기반, 다중언어요약 등이 있습니다.
Summarization
요약에 대한 방법론중에서, 가장 대표적이라고 할 수 있는, 큰 분류는 현재 추출요약과 생성요약이 있습니다.
일관성있는 문구와 접사를 자연스럽게 생성하는 모델이 필수적이기 때문에 어려운 생성요약 대신,
유연성은 부족하지만 입력에서 들어온 문서에서 구문들을 추출하여 중요문장을 찾는 추출요약을 판단해 보고 사용해보겠습니다.
What is Extractive Summarization
추출 요약은 일반적으로 원본 문서에서 가장 중요하다고 생각되는 문장을 선택하는 것으로 접근하고 있습니다.
이 때 원본 문서에서 어떻게 가장 중요한 문장인지 판단하는 방법은, 단어에 대한 가중치를 합하여 가장 높은 점수를 가진 문장을 선택합니다.
Input document → sentences similarity → weight sentences → select sentences with a higher rank.
여기서 다시 어떻게 단어에 대한 가중치를 판단할 것이냐에 따라 다양한 방법론들이 있습니다.
그 중 몇가지를 소개해보겠습니다.
Graph Base
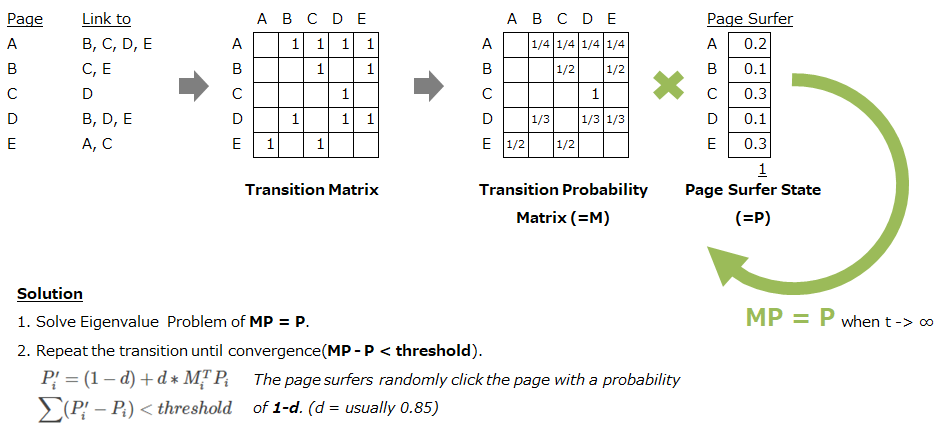
Textrank와 Lexrank같은 방법으로써 각 노드(단어)간의 관계를 고려하며 요약을 합니다.
페이지랭크가 더 많이 연결될 수록 더 좋은 페이지라고 판단한다면, 텍스트랭크는 각 문장에서 단어간의 동시등장빈도를 계산하여 좋은 단어를 판단합니다.
Feature Base
특징기반 모델은 문장의 단어들의 중요성을 판단한다. 뽑을 수 있는 특징들을 몇개 나열한다면 다음과 같습니다.
*Log-likelihood score
*Position of the sentence in input document
*Presence of the verb in the sentence
*Length of the sentence
*Term frequency
*Named entity tag NE
이런 특징들을 선택해서 회귀모델을 만들어 각 단어의 중요도를 뽑아낸 후에, 단어 중요도합이 가장 높은 문장을 산출합니다.
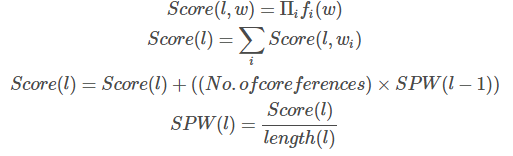 No.of coreferences는 이전 문장 대명사의 수입니다. 문장의 전반부에서 발생한 대명사를 세어 계산합니다. 점수는 이전 문장을 참조합니다.
No.of coreferences는 이전 문장 대명사의 수입니다. 문장의 전반부에서 발생한 대명사를 세어 계산합니다. 점수는 이전 문장을 참조합니다.
이 중에는 TF-IDF를 통해 요약하는 Hans Peter Luhn와 부정적인 단어를 감지하는 Edmundson Summarizer등이 있습니다.
Topic Base
주제에 기반한 계산은 문서의 주제와 각 문장이 어떤 주제가 포함된 이야기를 하는지 판단합니다.
Ted Dunning은 log-likelihood를 사용하여 topic signature를 측정합니다
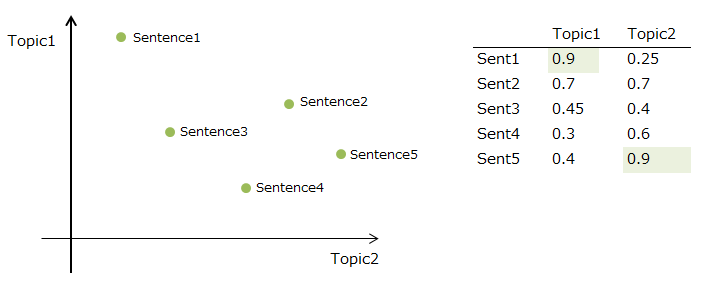
대표적으로 Latent Semanctic Analysis(LSA)을 통해 어떤 주제의 단어가 등장하는지 감지합니다.
이 LSA는 Singular Value Decomposition(SVD)에 기반합니다.
 그 외에 담론(Discourse)이라고 해서 텍스트 사이간의 의미론적 관계를 찾는 방법 (CST)나 TF-IDF와 베이지안(Bayesian)을 통해서도 주제를 찾기도 합니다.
그 외에 담론(Discourse)이라고 해서 텍스트 사이간의 의미론적 관계를 찾는 방법 (CST)나 TF-IDF와 베이지안(Bayesian)을 통해서도 주제를 찾기도 합니다.
Neural Network Base
신경망 방법으로 문장을 추출하는 방법으로는 2가지 프로세스로 구조화 할 수 있는데, 첫번째로 문장 표현을 벡터화하는 것과, 두번째로 벡터화한 문장을 고르는 것입니다. 이 문장표현과 문장을 따로따로 학습하거나 학습되있는 벡터를 가져와 맵핑하거나 군집화 할 수 있습니다.
——————————————————————————-
다음에는 SumBasic라는 단순히 단어의 등장확률을 통한 요약부터 TextRank, LexRank, 그리고 KL Summarizer 등을 직접 비교해보고,
단어의 등장확률이나 조건부확률, 단어의 극성등을 포함한 특징을 기반으로 한 지도학습으로 단어의 점수를 측정하고 이 단어들로 중요문장을 찾아보겠습니다.
•Text Summarization with Python
•Towards Automatic Text Summarization: Extractive Methods
Subscribe via RSS