Attention is All you need
by indexxlim
Attension is All you need
2018년 BERT라는 모델이 등장하면서 state-of-the-art를 차지했습니다. 이 BERT모델의 기반이 되는 Transformer 을 리뷰 합니다.
뉴옥 타임지에서 Oren Etzioni(chief executive of the Allen Institute for Artificial Intelligence)가 말하길, 기계가 아직 인간의 보통 감각을 표현할 수는 없지만, Bert는 폭발적인 발전의 순간이라고 합니다.
이 Bert 모델에 기초가 된 Transformer는 어텐션 매커니즘을 사용하여 Encoder-Decoder로 구성되는데, 여기서 어텐션 매커니즘이 어떻게 단어의 위치정보를 이용하여 어떤 단어를 주목하는지 살펴보겠습니다.
1. Abstract
전반적인 시퀀스 전달 모델은 인코더와 디코더를 포함하는 복잡한 순환(recurrent) 또는 합성곱(convolution)을 기반으로 합니다. 최고의 성능의 모델들은 또한 어텐션(attention) 을 통해 인코더와 디코더를 연결합니다. 우리는 새로운 단순한 네트워크 아키텍처인 트랜스포머를 오로지 어텐션 메커니즘에 기초하고, 순환과 합성곱을 완전히 배제하는 것을 제안합니다. 두 가지 기계 번역 작업에 대한 실험에서 이러한 모델은 보다 병렬적이고 상당히 필요한 동시에 품질이 우수하다는 것을 보여줍니다.
![]()
2. Introduction
Recurrent
연속전인 데이터를 처리하기 위해 이전까지 많이 쓰이던 모델은 순환(recurrent) 모델이었습니다. 순환 모델은 ht 번째에 대한 출력을 만들기 위해, t번째 입력과 ht-1번째 은닉 상태(hidden state)를 이용했습니다. 이를 이용해 데이터의 순차적인 특성을 모델에 유지시켜 왔습니다.
하지만 순환 모델의 경우 long-term dependency를 처리하는데 한계가 있습니다. Vanish gradient 문제는 LSTM과 GRU에서 어느 정도 해결해왔지만, 고정된 크기의 벡터에는 데이터의 특성을 고려하여 모든 정보를 압축할 수 없기 때문에 완전히 해결될 수 없었습니다. 예를 들어, “저는 언어학을 좋아하고, 인공지능 중에서도 딥러닝을 배우고 있고 자연어 처리에 관심이 많습니다.”라는 문장에서 ‘자연어’라는 단어를 만드는데 ‘언어학’이라는 단어는 중요한 단서입니다. 그러나, 두 단어 사이의 거리가 가깝지 않으므로 모델은 앞의 ‘언어학’이라는 단어를 이용해 자연어’라는 단어를 만들지 못하고, 언어학 보다 가까운 단어인 ‘딥러닝’을 보고 ‘이미지’를 만들 수도 있습니다. 이처럼, 어떤 정보와 다른 정보 사이의 거리가 멀 때 해당 정보를 이용하지 못하는 것이 long-term dependency problem입니다.
Recurrent model은 순차적인 특성이 유지되는 뛰어난 장점이 있었음에도, long-term dependency problem이라는 단점을 가지고 있습니다. 이와 달리 transformer는 순환이나 합성곱을 사용하지 않고 전적으로 어텐션 메커니즘만을 사용해 입력과 출력의 표현상태(representations)를 포착해냈습니다.
![]()
2. Introduction – Seq2Seq
Encoder and Decoder Stacks
대부분의 시퀀스를 다루는 모델들은 인코더-디코더 구조로 되어있습니다. 여기서 인코더는 입력 시퀀스를 연속적인 표현형태로 바꾸고 디코더는 이 표현형태을 통해 출력을 만들어 냅니다.
![]() 인코더 정보를 디코더에 전달할 수 있는 방식은 고정된 길이의 짧은 은닉 상태 벡터입니다. 이 은닉 상태 벡터는 디코더의 은닉 상태 입력으로 활용됩니다. 학습이 잘 되었다면 이 벡터에는 입력 문장에 대한 요약 정보를 포함하고 있을 것입니다. 초기 신경망 번역기는 이러한 방식으로 구현되었는데, 입력 문장이 길어지면서 심각한 성능저하가 일어나기 시작했습니다. 이 짧은 은닉 상태 벡터에 긴 시퀀스의 정보를 모두 저장하기엔 한계가 있었으며, 이러한 문제의 해결을 위해 어텐션 개념이 만들어졌습니다.
인코더 정보를 디코더에 전달할 수 있는 방식은 고정된 길이의 짧은 은닉 상태 벡터입니다. 이 은닉 상태 벡터는 디코더의 은닉 상태 입력으로 활용됩니다. 학습이 잘 되었다면 이 벡터에는 입력 문장에 대한 요약 정보를 포함하고 있을 것입니다. 초기 신경망 번역기는 이러한 방식으로 구현되었는데, 입력 문장이 길어지면서 심각한 성능저하가 일어나기 시작했습니다. 이 짧은 은닉 상태 벡터에 긴 시퀀스의 정보를 모두 저장하기엔 한계가 있었으며, 이러한 문제의 해결을 위해 어텐션 개념이 만들어졌습니다.
2. Introduction - Attension
Attension Mechanism
어텐션은 RNN과 같이 딥러닝 관련 레이어가 아니라 매커니즘으로, 특정 시퀀스를 출력하기 위해 입력 시퀀스의 어떠한 부분을 강조해야 될는지 학습을 할 수 있는 개념을 의미합니다. 물론 입출력 시퀀스가 자기 자신이 되는 셀프 어텐션 등 다양한 방식이 존재합니다.
![]()
어탠션 메커니즘은 간단히 말해서 특정 단어를 강조하는 것입니다. 입력 시퀀스 중에서 특정 단어와 다른 단어가 시퀀스에서 출현시 강조되는 것이며, 그러한 강조 정보가 입력 시퀀스에 적용되어서 디코더에 입력됩니다. 매 디코더 시퀀스마다 이러한 계산이 진행되며 수많은 문장이 학습되면서 인코더 디코더에 입력되는 단어들의 상호간의 컨텍스트가 학습됩니다.
![]()
원 논문에서는 t를 현재시점이라고 할 때, 인코더 출력벡터(s)와 은닉 상태 벡터(h)를 내적한 후에 소프트맥스(softmax)를 한다면 이를 어텐션 분포(attention distribution), 각각의 값을 어텐션 가중치(attention weight)라고 합니다. 이 가중치를 모두 더한다면 최종 출력 어텐션 값(attention value)이자 문맥 벡터(context vector)라고 정의 합니다. 그 후 실제 예측을 위해 어텐션 벡터와 인코더 출력벡터를 결합(concatenate)시켜 예측합니다.
2. Introduction – RC, LN
RC(Residual Connection)
residual connection을 수식으로 나타낸다면
$y_l=h(x_l )+F(x_l,W_l )$
여기서 $f(y_l )$는 ${x}_{l+1}$의 항등함수고 $h(x_l )$는 $x_l$ 로 맵핑됩니다.
이 때, $x_(l+1)$ ≡ $y_l$ 라고한다면,
$x_{(l+1)}=x_l+F(x_l,W_l )$ 이고
재귀적으로 $(x_{(l+2)}=x_{(l+1)}+F(x_{(l+1)},W_{(l+1)}) =x_l+ F(x_l, W_l)+F(x_{(l+1)},W_{(l+1)}), etc.).$
이 식을 미분하면 $\frac{∂ε}{∂x_l}=\frac{∂ε}{∂x_L} \frac{∂x_L}{∂x_l} = \frac{∂ε}{∂x_L} (1+\frac{∂}{∂x_l} \sum\limits^{L-1}_{i=1} F(x_i,W_i))$
여기서 $\frac{∂ε}{∂x_L}$ 는 모든 레이어에 적용 되고, F가 0이 되는 경우는 희박하기 때문에 가중치 $ε$ 가 매우 작더라도 Vanishing Gradient되는 경우는 거의 없습니다.
LN(Layer Normalization)
각 레이어의 출력을 평균과 표준편차를 이용해서 표준화(standardization)합니다.
3. Model Architecture
Encoder & Decoder
![]()
Encoder
인코더는 동일한 계층(layer)가 N개 반복되는 형태입니다. 이 논문에서는 6번 반복 했습니다. 그리고 각 계층은 두개의 하위 계층(sub-layer)로 구성됩니다. 첫 하위 계층은 멀티헤드(multi-head) 자가 어텐션 메커니즘(self-attention mechanism)이고 두번째는 간단하게 점별수렴(point-wise)하는 완전연결층(fc-layer)입니다. 그리고 모델 전체적으로 각 하위 계층에 RC(residual connection)가 전달됩니다. 즉 역전파가 계산되어 경사 하강이 될 때 원본 값을 더한후에 오차(Loss)가 계산됩니다. 그 후 계층 값을 레이어 정규화(Layer Normalization)합니다. 즉 각 하위 계층은 결과에 대해 잔차 값을 더하고 그 값을 레이어 정규화 한 값이 출력으로 나오게 됩니다. 그리고 모델 전체적으로 잔차 계산을 쉽게 하기 위해서 출력의 차원은 모두 512로 맞췄습니다.
Decoder
디코더도 인코더와 마찬가지로 동일한 계층이 N개 반복되는 형태입니다. 그리고 디코더도 6번 반복합니다. 그러나 반복되는 계층이 인코더와는 다르게 총 3개의 하위 계층으로 구성되어 있는데, 2개는 기존의 인코더의 하위 계층과 동일하고 나머지 하나는 인코더의 출력에 대해 멀티헤드 어텐션을 계산하는 하위 계층이 추가되었습니다. 디코더에서도 RC가 사용되었는데, 잔차 값을 더한 후 동일하게 계층들을 레이어 정규화 해줍니다. 그리고 자가 어텐션을 인코더와는 약간 다르게 수정을 했는데, 마스킹(masking)을 추가했습니다. 자가 어텐션을 할 때 현재 위치보다 뒤에 있는 단어는 변하지 못하도록 마스킹을 추가해준 것입니다. 다른위치의 단어는 auto-regressive한 특성을 이용해 알고 있는 정보로만 계산합니다.
![]()
Scaled Dot-Product Attention
Scaled Dot Product라는 의미는 Q와 K 사이를 내적하여 어텐션을 softmax를 통해 구하고, 그 후에 V를 내적하여 중요한 부분(attention)을 더 살린다는 메커니즘이 내포되어있습니다.
![]()
그리고 attention 부분은 자가 어탠션(self-attention)이 일어납니다. 자가 어탠션의 프로세스가 간단히 말하자면 각 경로에 대한 쿼리, 키 및 값 벡터를 만듭니다. 각 입력 토큰에 대해 쿼리 벡터를 사용하여 다른 모든 주요 벡터와 점수(score)를 계산합니다. 관련 점수를 곱한 후 값 벡터를 합산합니다.

해당 어텐션의 입력은 3가지입니다. D개 차원을 가지는 queries(Q)와 keys(K), values(V)로 구성됩니다. 먼저 Q는 주로 디코더의 은닉 상태 벡터, K는 인코더의 은닉 상태 벡터, V는 K에 정렬 모델(alignment model)로 계산된 어텐션 가중치입니다.
- Query: query는 다른 모든 단어에 대해 점수를 매기기 위해 사용되는 현재 단어의 표현이다(키 사용). 우리는 현재 진행중인 프로세스 토큰의 질의에만 신경을 쓴다.
- Key: key 벡터는 세그먼트에 있는 모든 단어에 대한 라벨과 같다. 관련된 단어들을 찾을 때 매칭된다.
- Value: value 벡터는 실제 단어 표현이다. 각 단어가 얼마나 관련이 있는지 계산되었을 떄, value를 이용해서 현재 단어의 가중치를 계산한다.
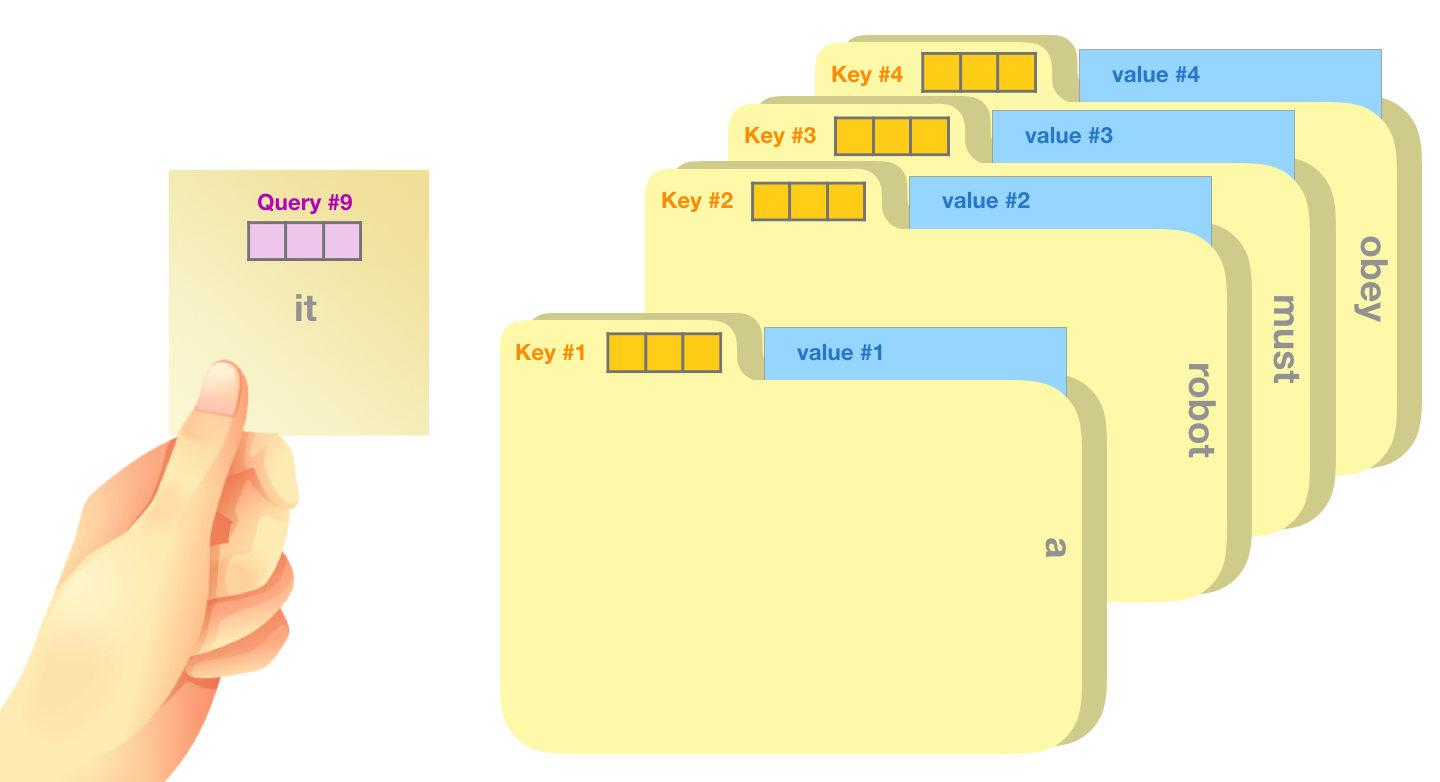 비유를 하자면, query는 연구하고 있는 주제를 가지고 있는 메모라고 한다면, key는 캐비닛 안에 있는 폴더의 태그과 같습니다. 태그를 스티커 메모와 일치시키면, 폴더의 내용은 value 입니다. 이 떄, 하나의 값만 찾는 것이 아니라 폴더의 혼합된 값의 조합을 찾습니다. 그래서 이 query 벡터와 각 키 vector를 곱한 값이 각 폴더의 점수입니다.
비유를 하자면, query는 연구하고 있는 주제를 가지고 있는 메모라고 한다면, key는 캐비닛 안에 있는 폴더의 태그과 같습니다. 태그를 스티커 메모와 일치시키면, 폴더의 내용은 value 입니다. 이 떄, 하나의 값만 찾는 것이 아니라 폴더의 혼합된 값의 조합을 찾습니다. 그래서 이 query 벡터와 각 키 vector를 곱한 값이 각 폴더의 점수입니다.
즉, 하나의 query에 대해 모든 key들과 내적을 한 뒤 각 값을 k의 차원수인 $\sqrt{d}_{k}$로 나눠주면서 스케일링 해줍니다. 그리고 소프트맥스 함수를 씌운 후 마지막으로 값을 곱합니다. $\ Attension(Q, K, V)=softmax(\frac{(QK^T)}{√(d_k)})V$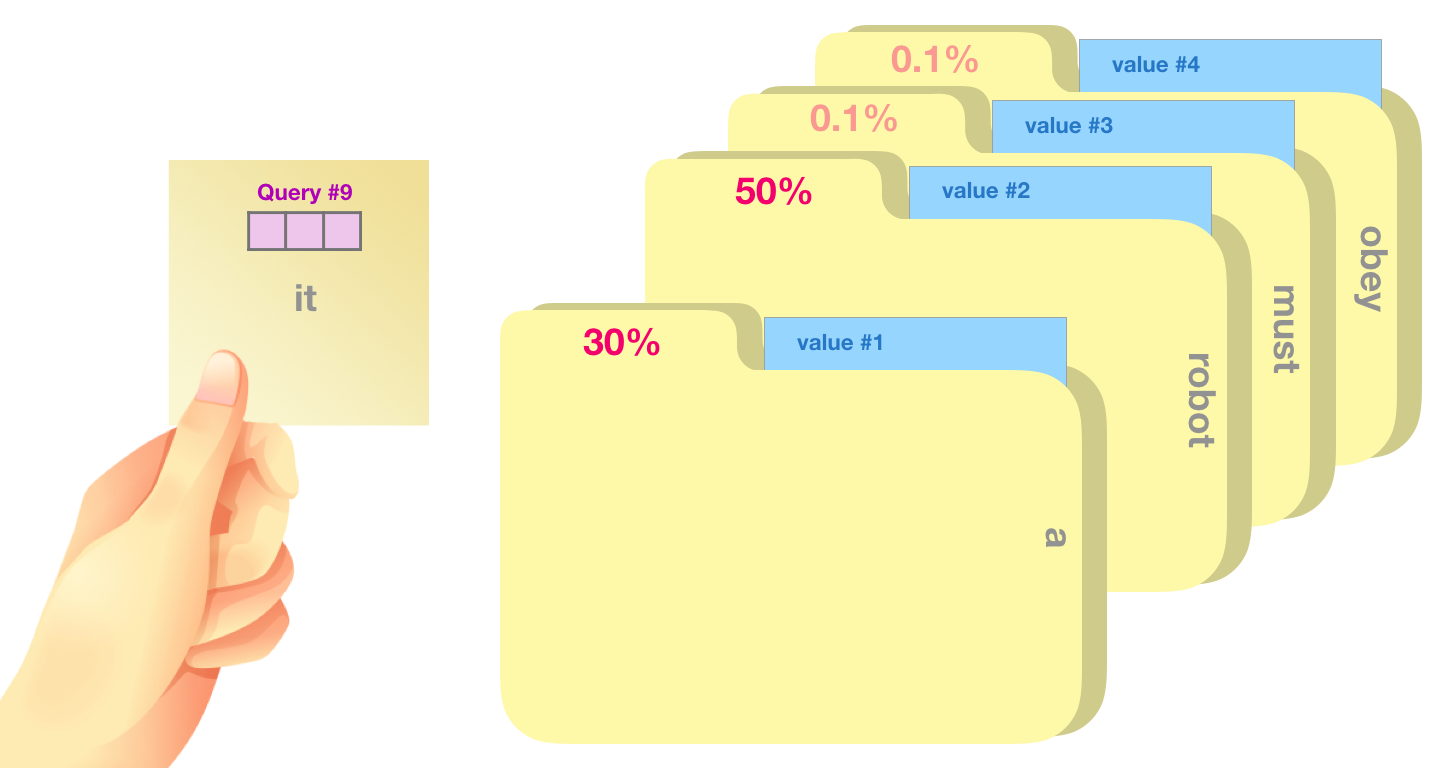
Multi-Head Attention
![]()
Query, key, value 들에 각각 다른 학습된 선형 투영(linear projection)을 h번 수행합니다. 즉, 동일한 Q,K,V에 각각 다른 weight matrix W를 곱합니다. 그 후 각각 어텐션을 병합(concatenate)합니다.
어텐션 레이어가 h개 씩으로 나눠짐에 따라 모델은 여러 개의 표현 공간(representation subspaces)들을 가지게 해줍니다. Query, key, Value weight 행렬들은 학습이 된 후 각각의 입력벡터들에게 곱해져 벡터들을단어의 정보에 맞추어 투영시키게 됩니다.
![]()
Position-wise Feed-Forward Networks
어텐션 하위 계층에서 fully connected feed-forward network 로 진행하는 과정입니다.
이 신경망은 두개의 선형 회귀으로 구성되어 있고 두 레이어 사이에 ReLU 함수를 사용합니다.
$\ FFN(x)=max(0,xW1+b1)W2+b2FFN(x)=max(0,xW1+b1)W2+b2$
Positional Encoding
해당 모델에서는 순환(recurrence)이나 합성곱(convolution)을 전혀 사용하지 않았기 때문에, 반드시 위치 정보를 넣어줘야 합니다. 따라서 positional encoding을 사용해서 입력 임베딩에 위치 정보를 넣어줍니다. 각 위치에 대해서 임베딩과 동일한 차원을 가지도록 인코딩을 해준 뒤 그 값을 임베딩값과 더해서 사용합니다.
![]()
positional encoding에는 여러 방법이 있지만 여기서는 sin, cos 함수를 사용해서 정형파로 구현해서 입력 문장길이에 대한 제약사항이 줄어듭니다.
각 위치 pos와 dimension i에 대한 positional encoding값은 다음과 같이 구합니다.
4. Why Self-Attention
이 모델에서는 순환 혹은 합성곱을 사용하지 않고 자가 어탠션(self-attention)만을 사용한 이유에 대해서 알아보면, 3가지 이유로 자가 어탠션을 선택합니다.
-
레이어당 전체 연산량이 줄어든다(시간복잡도).
-
병렬화가 가능한 연산량이 늘어난다.
-
거리가 먼 단어들의 종속성(long-range 또는 long-term dependency)때문
그리고 위의 3가지 외에 또 다른 이유는 어탠션을 사용하면 모델 자체의 동작을 해석하기 쉬워진다는(interpretable) 장점 때문입니다. 어탠션 하나의 동작 뿐만 아니라 multi-head의 동작 또한 어떻게 동작하는지 이해하기 쉽다는 장점이 있습니다.
![]()
5. 결론
본 연구에서는, 전적으로 주의를 기반으로 한 최초의 시퀀스 전달 모델인 Transformer를 제시하여, 인코더-디코더 아키텍처에서 가장 일반적으로 사용되는 순환 레이어를 multi-headed self-attention로 대체하였습니다.
번역 작업의 경우, Transformer는 순환 또는 합성곱 레이어에 기반한 구조보다 훨씬 더 빠르게 훈련될 수 있습니다. WMT 2014 영어-독일어 및 WMT 2014 영어-프랑스어 번역 과제 모두에서 SOTA를 달성했습니다. 이전의 과제에서 우리의 최고의 모델이 이전에 보고된 모든 앙상블보다 더 성능이 좋습니다. 우리는 관심 기반 모델의 미래에 대해 흥분하고 있으며 다른 과제에 적용할 계획입니다. Transformer를 텍스트 이외의 입력 및 출력으로 확장하고 영상, 오디오, 비디오 등에서 대용량 입력과 출력을 효율적으로 처리하기 위한 국부적이고 제한된 어탠션 메커니즘을 조사할 계획입니다. 우리의 또 다른 연구 목표는 덜 순차적으로 발전하는 것입니다.
Reference
•Transformer
•Attention
•Residual Connection
•Layer Normalization
•Label Smoothing
•The Illustrated Transformer
•The Illustrated GPT-2 (Visualizing Transformer Language Models)
•https://pozalabs.github.io/transformer/
•http://freesearch.pe.kr/archives/4876#easy-footnote-bottom-2-4876
•https://wikidocs.net/22893
Subscribe via RSS